Estamos vivendo a grande era dos dados. Por isso, é importante contar com ferramentas como a Hadoop ou Spark, utilizadas para preparar, processar, gerenciar e analisar grandes conjuntos de dados.
Há pouco tempo, nosso cotidiano era marcado por grandezas que giravam em torno de gigabytes (109 bytes) e terabytes (1012 bytes). Nos dias atuais, as grandezas estão na escala dos petabytes (1015 bytes) e, por que não, na escala dos exabytes (1018 bytes).
Um importante estudo realizado pela IDC – International Data Corporation apontou que a quantidade total de dados no mundo em 2012 era de 2,8 Zettabytes (1021 bytes) e que em 2020 esse total de dados chegaria a 40 zettabytes. O estudo previu que, a partir de 2012, a quantidade de dados total iria dobrar a cada dois anos.
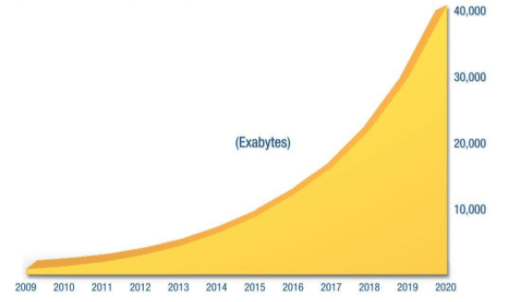
O Universo Digital: crescimento dos dados em 50 vezes, do início de 2010 até o fim de 2020. Fonte: IDC – Dezembro de 2012.
Diante desse grande volume de dados, como utilizar toda essa informação disponível para orientar os negócios, por exemplo? É o que veremos a seguir.
A importância de ferramentas de big data
Ainda de acordo com a IDC, estimava-se que em 2012, 25% dos dados totais eram úteis para processamento Big Data e que em 2020 esse percentual chegaria a 33%. No entanto, dos 25% de dados úteis, apenas 3% eram classificados e 0,5% efetivamente analisados.
Nesse sentido, o estudo previu que até 2020 esse percentual de dados classificados e analisados aumentasse consideravelmente, conforme apresentado no gráfico abaixo, de Oportunidades do Big Data.

Oportunidades do Big Data. Fonte: IDC – Dezembro de 2012
< Aprenda com este outro artigo: Ciência de Dados – conheça a profissão do futuro />
O que significa, na prática, se mais dados pudessem ser classificados e analisados?
Bem, o aumento da quantidade de dados classificados e analisados pode resultar em valiosas informações para a tomada de decisão em diversas áreas da sociedade. O processo de análise dessa grande quantidade de dados é encarado como uma grande oportunidade e desafio para os especialistas da área.
Isso porque essas análises exigem volumosos investimentos em infraestrutura computacional, ferramentas e recursos humanos especializados.
Mas, essa evolução tem um lado positivo. Ainda segundo a IDC, o custo de cada gigabyte teria uma redução de preço saindo de $2 (dois dólares) em 2012 para $0.20 (vinte centavos de dólar) em 2020, conforme apresentado no gráfico abaixo. Essa queda de preços contribui diretamente para o aumento da quantidade de dados classificados e analisados.
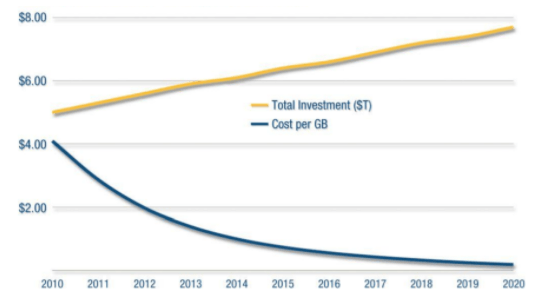
Queda do custo e aumento do investimento. Fonte: IDC – Dezembro de 2012
Os investimentos necessários para transformar toda essa grande quantidade de dados em informação e conhecimento inevitavelmente passará pela pesquisa e desenvolvimento de ferramentas de processamento distribuído, principalmente por meio de software frameworks, que facilitam o trabalho dos desenvolvedores de software.
Essas ferramentas já realizam automaticamente a distribuição do processamento, permitindo que os desenvolvedores mantenham o foco no que realmente importa: o negócio. Diante dessa necessidade surgiram diversas ferramentas de big data (frameworks) para processamento distribuído, como Apache Hadoop ou Spark.
Veremos mais sobre o sistema Hadoop e a tecnologia Spark na sequência.
< Leia também: Bootstrap – como usar e para o que serve esse framework? />
Hadoop ou Spark? Conheça cada uma delas
Antes de respondermos essa pergunta, vamos apresentar cada um desses frameworks. Você verá com mais detalhes, abaixo, as características tanto do sistema Hadoop quanto da tecnologia Spark.
Tecnologia Hadoop
A tecnologia hadoop foi criada em 2007 baseado no modelo MapReduce (um modelo de programação para processamento paralelo de grandes volumes de dados distribuídos em clusters).
O objetivo do Hadoop na prática era ser uma ferramenta escalável e tolerante a falhas. Nela, os dados são tratados como pares chave/valor (Key/Value) e processados por meio de duas funções principais, Map e Reduce.
Mesmo possuindo algumas deficiências, como a dificuldade de lidar com algoritmos iterativos, devido a necessidade de gravação dos dados em disco a cada iteração, o Hadoop reinou por muito tempo como o framework mais utilizado para processamento Big Data.
Grandes empresas em todo o mundo obtiveram bons resultados com o Hadoop na prática, devido ao seu sistema de arquivos distribuídos (HDFS) e outros sistemas que compõem seu ecossistema, tais como HBase, Hive, Pig e Mahout.
Apesar de apresentar bons resultados de tempo de execução, consumo de recursos e escalabilidade, com o tempo observou-se que a ferramenta apresentava uma deficiência crucial, que era o excesso de gravações de dados no disco.
Essa característica acrescentava tempo considerável (overhead) às aplicações interativas, referentes à leitura e à gravação em disco a cada iteração do algoritmo.
Tecnologia Spark
Com o objetivo de ser mais uma opção de framework distribuído, tolerante a falhas e escalável, surgiu em 2010 o Apache Spark, com o propósito de ser uma ferramenta com capacidade de manipular grandes massas de dados em memória. O sistema é também mais eficiente que o modelo MapReduce para aplicações executando em disco.
Em alguns testes realizados, o Spark alcançou números impressionantes ao produzir resultados até 100 vezes mais rápidos que o Hadoop, para algumas aplicações específicas.
O Spark surgiu para suprir a principal deficiência do modelo MapReduce e da ferramenta Hadoop, apresentando-se como uma importante alternativa para solução de problemas que exigem a implementação de algoritmos iterativos.
Entretanto, o Spark tem a característica de usar muita memória RAM para o processamento e armazenamento de dados intermediários das iterações do algoritmo. Caso não exista memória suficiente disponível, o Spark começará a utilizar o disco para armazenamento e funcionará de maneira
O Apache Spark vai substituir o Hadoop?
Como vimos, o Hadoop é uma estrutura de processamento de dados paralelo que tem sido tradicionalmente usada para executar tarefas de mapeamento/redução. Esses são trabalhos de longa duração que levam minutos ou horas para serem concluídos.
Já o Spark foi projetado para ser executado em cima do Hadoop e é uma alternativa ao modelo tradicional de mapeamento/redução em lote que pode ser usado para processamento de dados de fluxo em tempo real e consultas interativas rápidas que terminam em segundos. Portanto, o Hadoop suporta tanto o mapa/redução tradicional quanto o Spark.
Para responder a pergunta deste tópico, devemos olhar para o Hadoop como uma estrutura de propósito geral que suporta vários modelos e devemos olhar para o Spark como uma alternativa ao Hadoop MapReduce em vez de um substituto para o Hadoop.
Preciso aprender o Hadoop primeiro para aprender o Apache Spark?
Não, você não precisa aprender Hadoop para aprender Spark. Spark foi um projeto independente.
Mas, depois do YARN (que fornece gestão de recursos para os processos que estão sendo executados no Hadoop) e do Hadoop 2.0, o Spark se tornou popular porque este pode ser executado em cima do HDFS (sistema escalável baseado em Java que armazena dados em diversas máquinas, sem organização prévia) junto com outros componentes do Hadoop.
Assim, o Spark se tornou outro mecanismo de processamento de dados no ecossistema Hadoop e é bom para todas as empresas e comunidades, pois fornece mais capacidade para o Hadoop.
Para os desenvolvedores, quase não há sobreposição entre os dois. Hadoop é uma estrutura na qual você escreve o trabalho MapReduce herdando classes Java. Spark é uma biblioteca que permite computação paralela por meio de chamadas de função.
Para os operadores que executam um cluster, há uma sobreposição de habilidades gerais, como configuração de monitoramento e implantação de código.
Hadoop ou Spark: qual é a melhor?
Finalmente, chegamos à grande pergunta por trás de toda essa história – qual a melhor opção: Hadoop ou Spark?
Para responder essa questão, devemos analisar algumas variáveis, como o problema a ser trabalhado, a experiência do desenvolvedor em lidar com as ferramentas e, principalmente, os recursos computacionais disponíveis.
Se o conjunto de máquinas (cluster) que vai ser utilizado possui muita memória RAM disponível e o algoritmo a ser implementado tem a característica de ser iterativo, talvez o Spark seja a melhor solução.
Por outro lado, se a quantidade de memória RAM no cluster é pequena e o algoritmo não tem a característica de interatividade, a melhor solução pode ser ainda o bom e velho Hadoop.
Tudo isso ainda dependerá da experiência do desenvolvedor em lidar com cada um dos frameworks, pois essa questão sempre afeta o tempo de desenvolvimento das soluções.
Hadoop ou Spark: qual escolher?
Conclusão
O Spark surgiu como uma alternativa viável ao Hadoop. Entretanto, necessita de grandes quantidades de memória RAM para o seu efetivo funcionamento.
O Hadoop ainda é muito utilizado e se apresenta como uma boa solução para uma grande quantidade de aplicações de diversos tamanhos e características.
Cabe ao desenvolvedor e ao administrador de sistemas Big Data avaliarem cada uma das variáveis acima e decidir pelo uso do framework que mais se adequa ao problema a ser resolvido e ao orçamento que será destinado.
Agora que você já sabe o que ponderar na hora de escolher entre hadoop ou spark, é importante estar atualizado e se especializar nessa área para se manter relevante e ser um profissional procurado no mercado de trabalho. A XP Educação ajuda você nisso!
Além dos cursos de graduação e de MBA em Ciência de Dados, a XP também disponibiliza bootcamps na área de Data Science, como o de arquitetura de Big Data. Nele, você aprende a construir aplicações inteligentes a partir do processamento e análise de grandes volumes de dados nas plataformas dos maiores players do mercado.
Domine Big Data, coleta e obtenção de dados, processamentos, modelagens e muito mais. Assine agora!



{kind=link}